This is the multi-page printable view of this section. Click here to print.
Getting Started
1 - Hardware Requirements
Setting up a Kowabunga platform requires you to provide the following hardware:
- 1x Kahuna instance (more could used if high-availability is expected).
- 1x Kiwi instance per-region (2x recommended for production-grade)
- 1x Kaktus instance per-region (a minimum of 3x recommended for production-grade, can scale to N).
Important
Note that while it should work on any kind of Linux distribution, Kowabunga has only been tested (understand it as supported) with Ubuntu LTS. Kowabunga comes pre-packaged for Ubuntu.Kahuna Instance
Kahuna is the only instance that will be exposed to end users. It is recommended to have it exposed on public Internet, making it easier for DevOps and users to access to but there’s no strong requirement for that. It is fairly possible to keep it local to your private corporate network, only accessible from on-premises network or through VPN.
Hardware requirements are lightweight:
- 2-cores vCPUs
- 4 to 8 GB RAM
- 64 GB for OS + MongoDB database.
Disk and network performance is fairly insignificant here, anything modern will do just fine.
We personnally use and recommend using small VPS-like public Cloud instances. They come with public IPv4 address and all that one needs for a monthly price of $5 to $20 only.
Kiwi Instance
Kiwi will act as a network software router and gateway. Even more than for Kahuna, you don’t need much horse-power here. If you plan on setting your own home labs, a small 2 GB RAM Raspberry Pi would be sufficient (keep in mind that SoHo routers and gateways are lightweight than that).
If you intend to use it for enteprise-grade purpose, just pick the lowest end server you could fine.
It’s probably going to come bundled with 4-cores CPU, 8 GB of RAM and whatever SSD and in any cases, it would be more than necessary, unless you really intend to handle 1000+ computing nodes being a multi-Gbps traffic.
Kaktus Instance
Kaktus instance are another story. If there’s one place you need to put your money on, here would be the place. The instance will handle as many virtual machines as can be and be part of the distributed Ceph storage cluster.
Sizing depends on your expected workload, there’s no accurate rule of thumb for that. You’ll need to think capacity planning ahead. How much vCPUs do you expect to run in total ? How many GBs of RAM ? How much disk ? What overcommit ratio do you expect to set ? How much data replication (and so … resilience) do you expect ?
These are all good questions to be asked. Note that you can easily start low with only a few Kaktus instances and scale up later on, as you grow. The various Kaktus instances from your fleet may also be heterogeneous (to some extent).
As a rule of thumb, unless you’re doing setting up a sandbox or home lab, a minimum of 3 Kaktus instance would be recommended. This allows you to move workload from one to another, or simply put one in maintenance mode (i.e. shutdown workload) while keeping business continuity.
Supposing you have X Kaktus instances and expect up to Y to be down at a given time, the following applies:
Instance Maximum Workload: (X - Y) / X %
Said differently, with only 3 machines, don’t go above 66% average load usage or you won’t be able to put one in maintenance without tearing down application.
Consequently, with availability in mind, better have more lightweight instances than few heavy ones.
Same applies (even more to Ceph storage cluster). Each instance local disk will be part of Ceph cluster (a Ceph OSD to be accurate) and data will be spread across those, from the same region.
Now, let’s consider you want to achieve 128 TB usable disk space. At first, you need to define your replication ratio (i.e. how many time objects storage fragments will be replicated across disks). We recommend a minimum of 2, and 3 for production-grade workloads. That means you’ll actually need a total of 384 TB of physical disks.
Here are different options to achieve it:
- 1 server with 24x 16TB SSDs each
- 3 servers with 8x 16TB SSDs each
- 3 servers with 16x 8TB SSDs each
- 8 servers with 6x 8TB SSDs each
- […]
From a purely resilient perspective, last option would be the best. It provides the more machines, with the more disks, meaning that if anything happens, the smallest fraction of data from the cluster will be lost. Lost data is possibly only ephemeral (time for server or disk to be brought up again). But while down, Ceph will try to re-copy data from duplicated fragments to other disks, inducing a major private network bandwidth usage. Now whether you only have 8 TB of data to be recovered or 128 TB may have a very different impact.
Also, as your virtual machines performance will be heavily tight to underlying network storage, it is vital (at least for production-grade workloads) to use NVMe SSDs with 10 to 25 Gbps network controllers and sub-millisecond latency between your private region servers.
So let’s recap …
Typical Kaktus instances for home labs or sandbox environments would look like:
- 4-cores (8-threads) CPUs.
- 16 GB RAM.
- 2x 1TB SATA or NVMe SSDs (shared between OS partition and Ceph ones)
- 1 Gbps NIC
While Kaktus instances for production-grade workload could easily look like:
- 32 to 128 cores CPUs.
- 128 GB to 1.5 TB RAM.
- 2x 256 GB SATA RAID-1 SSDs for OS.
- 6 to 12x 2-8 TB NVMe SSDs for Ceph.
- 10 to 25 Gbps NICs with link-agregation.
Important
Remember that you can start low and grow later on. All instances must not need to be alike (you can perfectly have “small” 32-cores servers and higher 128-cores ones). But completely heterogenous instances (especially on disk and network constraints) could have disastrous effects.
Keep in mind that all disks form all instances will be part of the same Ceph cluster, where any virtual machine instance can read and write data from. Mixing 25 Gbps network servers with fast NVMe SSDs with low-end 1 Gbps one with rotational HDDs would lower down your whole setup.
2 - Software Requirements
Kowabunga’s deployment philosophy relies on IaC (Infrastructure-as-Code) and CasC (Configuration-as-Code). We heavily rely on:
Kobra Toolchain
While natively compatible with the aformentionned, we recommend using Kowabunga Kobra as a toolchain overlay.
Kobra is a DevOps deployment swiss-army knife utility. It provides a convenient wrapper over OpenTofu, Ansible and Helmfile with proper secrets management, removing the hassle of complex deployment startegy.
Anything can be done without Kobra, but it makes things simpler, not having to care about the gory details.
Kobra supports various secret management providers. Please choose that fits your expected collaborative work experience.
At runtime, it’ll also make sure you’re OpenTofu / Ansible toolchain is properly set on your computer, and will do so otherwise (i.e. brainless setup).
Installation can be easily performed on various targets:
Installation Ubuntu Linux
Register Kowabunga APT repository and then simply:
$ sudo apt-get install kobra
Installation on macOS
macOS can install Kobra through Homebrew. Simply do:
$ brew tap kowabunga/cloud https://github.com/kowabunga-cloud/homebrew-tap.git
$ brew update
$ brew install kobra
Manual Installation
Kobra can be manually installed through released binaries.
Just download and extract the tarball for your target.
Tips
Note that kobra is a simple wrapper around your favorite tools. If things don’t go as planned, you can turn on the debug flag, which will comes in handy (or simply show you what exact caommand-line is being invoked), e.g.
$ KOBRA_DEBUG=1 kobra ...
Setup Git Repository
Kowabunga comes with a ready-to-consumed platform template. One can clone it from Git through:
$ git clone https://github.com/kowabunga-cloud/platform-template.git
or better, fork it in your own account, as a boostraping template repository.
Secrets Management
Passwords, API keys, tokens … they are all sensitive and meant to be secrets. You don’t want any of those to leak on a public Git repository. Kobra relies on SOPS to ensure all secrets are located in an encrypted file (which is safe to to be Git hosted), which can be encrypted/decrypted on the fly thanks to a master key.
Kobra supports various key providers:
- aws: AWS Secrets Manager
- env: Environment variable stored master-key
- file: local plain text master-key file (not recommended for production)
- hcp: Hashicorp Vault
- input: interactive command-line input prompt for master-key
- keyring: local OS keyring (macOS Keychain, Windows Credentials Manager, Linux Gnome Keyring/KWallet)
If you’re building a large production-grade system, with multiple contributors and admins, using a shared key management system like aws or hcp is probably welcome.
If you’re single contributor or in a very small team, storing your master encryption key in your local keyring will do just fine.
Simply edit your kobra.yml file in the following section:
secrets:
provider: string # aws, env, file, hcp, input, keyring
aws: # optional, aws-provider specific
region: string
role_arn: string
id: string
env: # optional, env-provider specific
var: string # optional, defaults to KOBRA_MASTER_KEY
file: # optional, file-provider specific
path: string
hcp: # optional, hcp-provider specific
endpoint: string # optional, default to "http://127.0.0.1:8200" if unspecified
master_key_id: string
As an example, managing platform’s master key through your system’s keyring is as simple as:
secrets:
provider: keyring
master_key_id: my-kowabunga-labs
As a one-time thing, let’s init our new SOPS key pair.
$ kobra secrets init
▶ [INFO 00001] Issuing new private/public master key ...
▶ [INFO 00002] New SOPS private/public key pair has been successuflly generated and stored
Warning
If you’ve lost this master key, your whole system becomes compromised.
There’s no way to restore it.
We more than heavily recommend you to backup the generated master key in a secondary vault of your choice.
You can easily extract the base64-encoded key through:
$ kobra secrets get --yes-i-really-mean-it
Alternatively, you can share it with a contributor or have it re-imported (or rotated) through:
kobra secrets set --yes-i-really-mean-it -k MY_BASE64_ENCODED_MASTER_KEY
Ansible
The official Kowabunga Ansible Collection and its associated documentation will seamlessly integrate with SOPS for secrets management.
Thanks to that, any file from your inventory’s host_vars or group_vars directories, being suffixed as .sops.yml will automatically be included when running playbooks. It is then absolutely safe for you to use these encrypted-at-rest files to store your most sensitive variables.
Creating such files and/or editing these to add extra variables is then as easy as:
$ kobra secrets edit ansible/inventories/group_vars/all.sops.yml
Kobra will automatically decrypt the file in-live, open the editor of your choice (as stated in your $EDITOR env var), and re-ecnrypt it with the master key at save/exit.
That’s it, you’ll never have to worry about secrets management and encryption any longer !
OpenTofu
The very same applies for OpenTofu, where SOPS master key is used to encrypt the most sensitive data. Anything sensitive you’d need to add to your TF configuration can be set in the terraform/secrets.yml file as simple key/value.
$ kobra secrets edit terraform/secrets.yml
Note however that their existence must be manually reflected into HCL formatted terraform/secrets.tf file, e.g.:
locals {
secrets = {
my_service_api_token = data.sops_file.secrets.data.my_service_api_token
}
}
supposing that you have an encrypted my_service_api_token: ABCD…Z entry in your terraform/secrets.yml file.
Note that OpenTofu adds a very strong feature over plain old Terraform, being TF state file encryption. Where the TF state file is located (local, i.e. Git or remotely, S3 or alike) is up to you, but shall you use a Git located one, we strongly advise to have it encrypted.
You can achieve this easily by extending the terraform/providers.tf file in your platform’s repository:
terraform {
encryption {
key_provider "pbkdf2" "passphrase" {
passphrase = var.passphrase
}
method "aes_gcm" "sops" {
keys = key_provider.pbkdf2.passphrase
}
state {
method = method.aes_gcm.sops
}
plan {
method = method.aes_gcm.sops
}
}
}
variable "passphrase" {
# Value to be defined in your local passphrase.auto.tfvars file.
# Content to be retrieved from decyphered secrets.yml file.
sensitive = true
}
Then, create a local terraform/passphrase.auto.tfvars file with the secret of your choice:
passphrase = "ABCD...Z"
Warning
Note that you don’t want the terraform/passphrase.auto.tfvars (being plain-text) file to be stored on Git, so make sure it is well ignored in your .gitignore configuration.
Also, it’s strongly advised that whatever passphrase you’d chose to encrypt TF state is kept secure. A good practice would be to have it copied and defined in terraform/secrets.yml file, as any other sensitive variable, so to keep it vaulted.
3 - Network Topology
Let’s use this sample network topology for the rest of this tutorial:
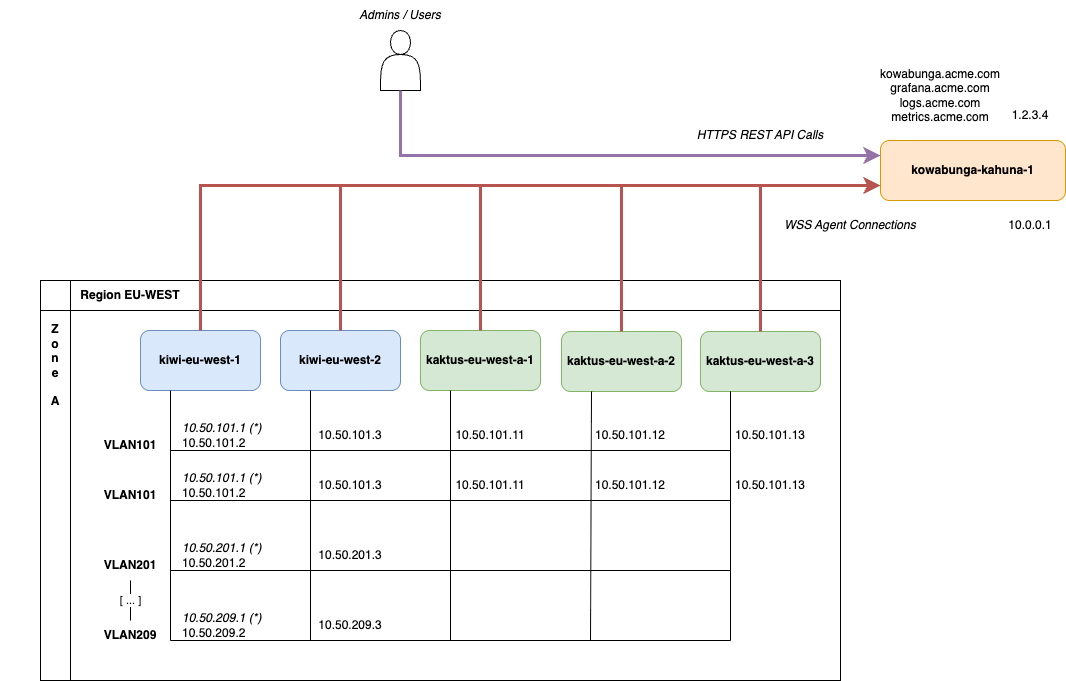
We’ll start with a single Kahuna instance, with public Internet exposure. The instance’s hostname will be kowabunga-kahuna-1 and it has 2 network adapters and associated IP addresses:
- a private one, 10.0.0.1, in the event we’d need to peer further one with other instances for hugh-availability.
- a public one, 1.2.3.4, exposed as kowabunga.acme.com for WebUI, REST API calls to the orchestrator and WebSocket agents endpoint. It’ll also be exposed as grafana.acme.com, logs.acme.com and metrics.acme.com for Kiwi and Kaktus to push logs and and metrics and allow for service’s metrology.
Next is the main (and only) region, EU-WEST and its single zone, EU-WEST-A. The region/zone will feature 2 Kiwi instances and 3 Kaktus ones.
All instances will be connected under the same L2 network layer (as defined in requirements) and we’ll use different VLANs and associated network subnets to isolate content:
- VLAN 0 (i.e. no VLAN) will be used as public segment, with associated RIPE block 4.5.6.0/26. All Kaktus instances will be able to bind these public IPs and translate those to Kompute virtual machine instances through bridged network adapters.
- VLAN101 will be used as default, administration VLAN, with associated 10.50.101.0/24 subnet. All Kiwi and Kaktus instances will be part of.
- VLAN102 will be used for Ceph backpanel, with associated 10.50.102.0/24 subnet. While not mandatory, this allows differentiating the administrative control plane traffic from pure storage cluster data synchronization. This allows for better traffic shaping and monitoring, if ever needs be. Note that on enterprise-grade production systems, Ceph project would recommend to use dedicated NIC for Ceph traffic, so isolation here makes sense.
- VLAN201 to VLAN209 would be application VLANs. Kiwi will bind them, being region’s router, but Kaktus don’t. Instantiated VMs will however, through bridged network adapters.